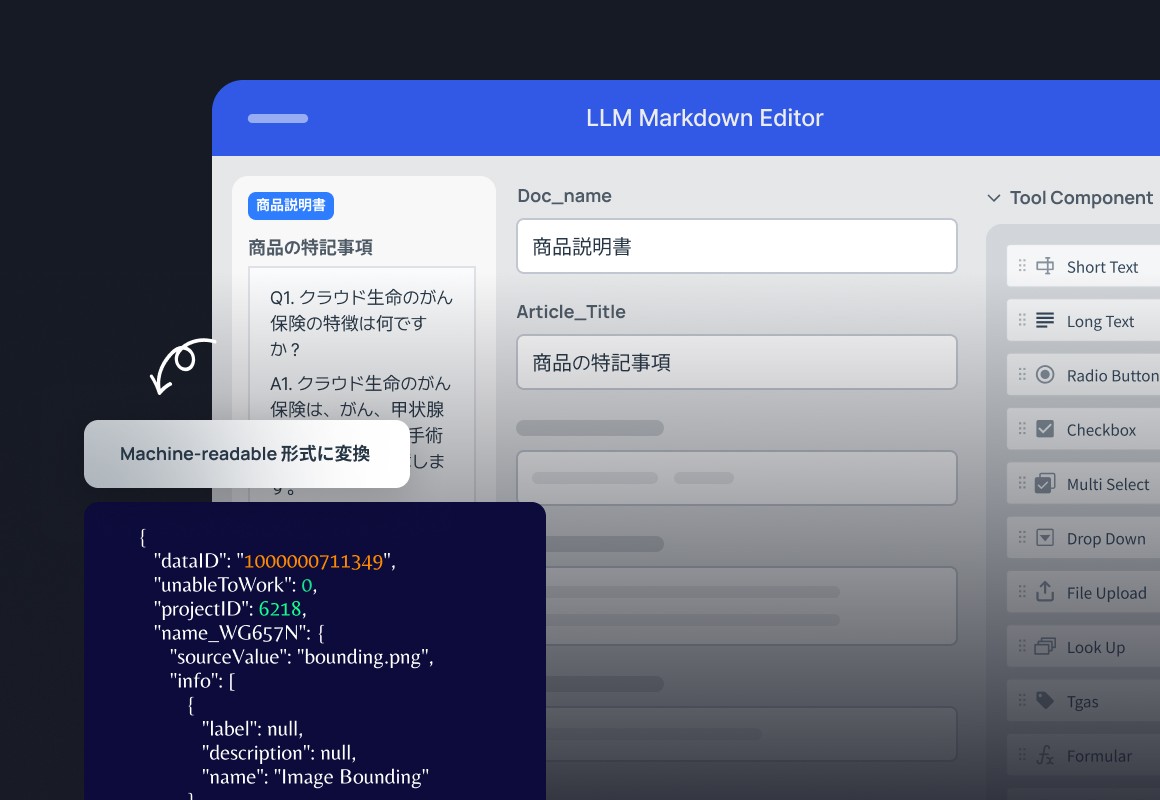
Data Engine
企業カスタマイズ型LLMに必要な高品質なデータを構築します
構築に関するお問い合わせ




Why Crowdworks AI
クラウドワークスは選ばれる理由があります
01
データが左右する企業カスタマイズ型LLMの性能
基盤モデルの性能がいくら優れていても企業が使用するLLMは、各企業のPrivate Dataを十分に学習してこそ効果的に活用できます。Crowdworks AIは企業向けのカスタマイズされたLLMのためのさまざまなデータ構築に豊富な経験を持っています。
02
世界屈指のAIデータ専門企業
韓国1位のAIデータ専門企業のCrowdworks AIはアメリカのGartner社、CB Insightsの報告書にデータ加工分野で世界屈指の企業として登載されました
03
500社以上のAI先頭企業が選択
KOSPI Top30のIT企業の70%以上がAI開発にCrowdworks AIのデータソリューションを選択しました。
04
データ設計、加工、構築への深い理解
累積2億5千万件以上のデータ構築、1千件以上の企業プロジェクト経験を基にAIデータへの深い理解を持つ専門家がプロジェクトに参加します。
NAVER
D2SFのリーダー、ヤン・サンファン
"Crowdworks AIでAI開発の処理にかかる莫大な時間と費用を減らすことができました。
現在のClovaやPapagoの性能は
Crowdworks AIが作ったと言っても過言ではありません。"
How We Work
企業カスタマイズ型LLMに特化したデータを構築します。
1
ファインチューニング用のデータセット構築
データ専門家達が企業の活用目的に合わせて、既存のLLMモデルをファインチューニングする時に必要な特化したデータセットを構築いたします。

表現力の最大化のためのデータセット
モデルの回答が特定のビジネス環境のニーズを反映するように設計

産業特化用データセット
モデルの回答が特定の産業の高度化された知識を反映するように設計
2
RLHF、DPO等、強化学習用のヒューマンフィードバックデータ構築
人間のフィードバックによる強化学習(Reinforcement Learning from Human Feedback)、直接優先最適化(Direct Preference Optimization)等、強化学習のためのデータを構築します。

モデルの回答を評価したデータ構築を通じてカスタマイズ型LLMの品質向上
LLM目的による自己評価項目を基準としてフィードバック
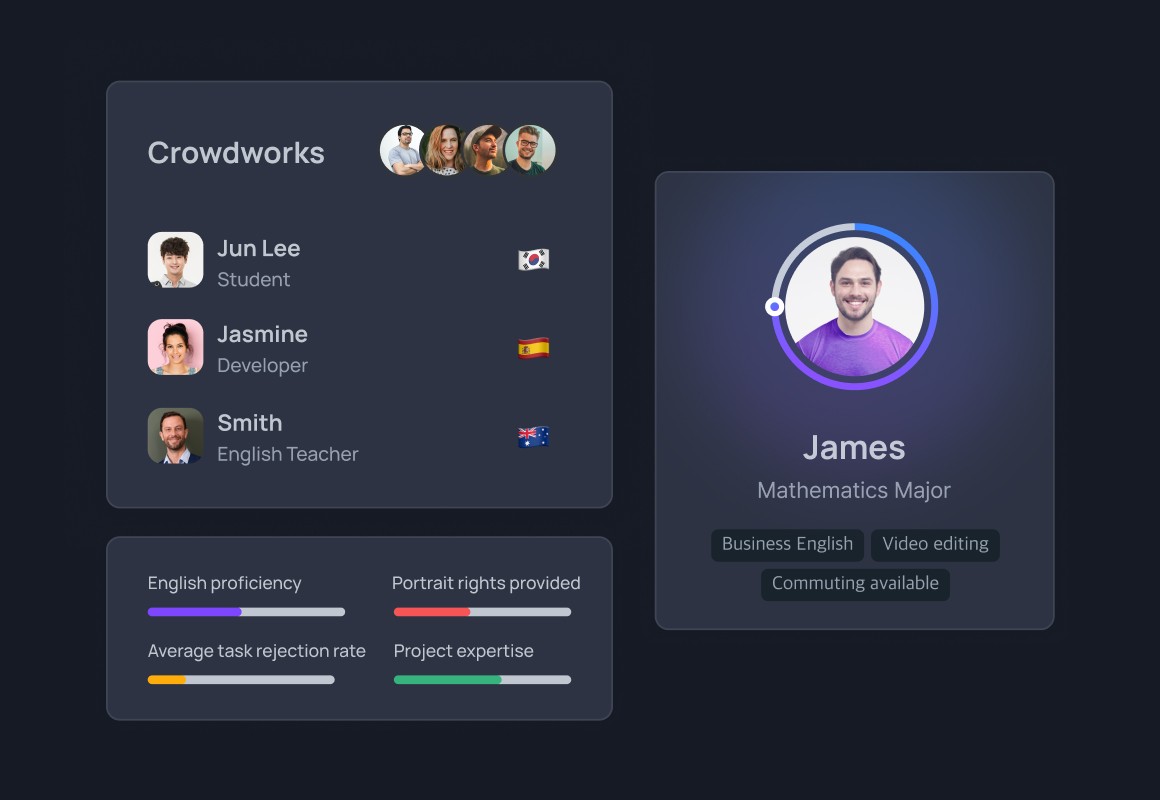
検証された作業者が参加
クラウドソーシングを通じて多様かつ検証された作業者の募集および参加
3
社内データの資産化
RAGを通じて内部データを最も効果的に活用できるようデータを加工し、構造化します。