
How We Work
LLM導入のあらゆる段階でコンサルティングとサービスを提供します


Enterprise Challenges
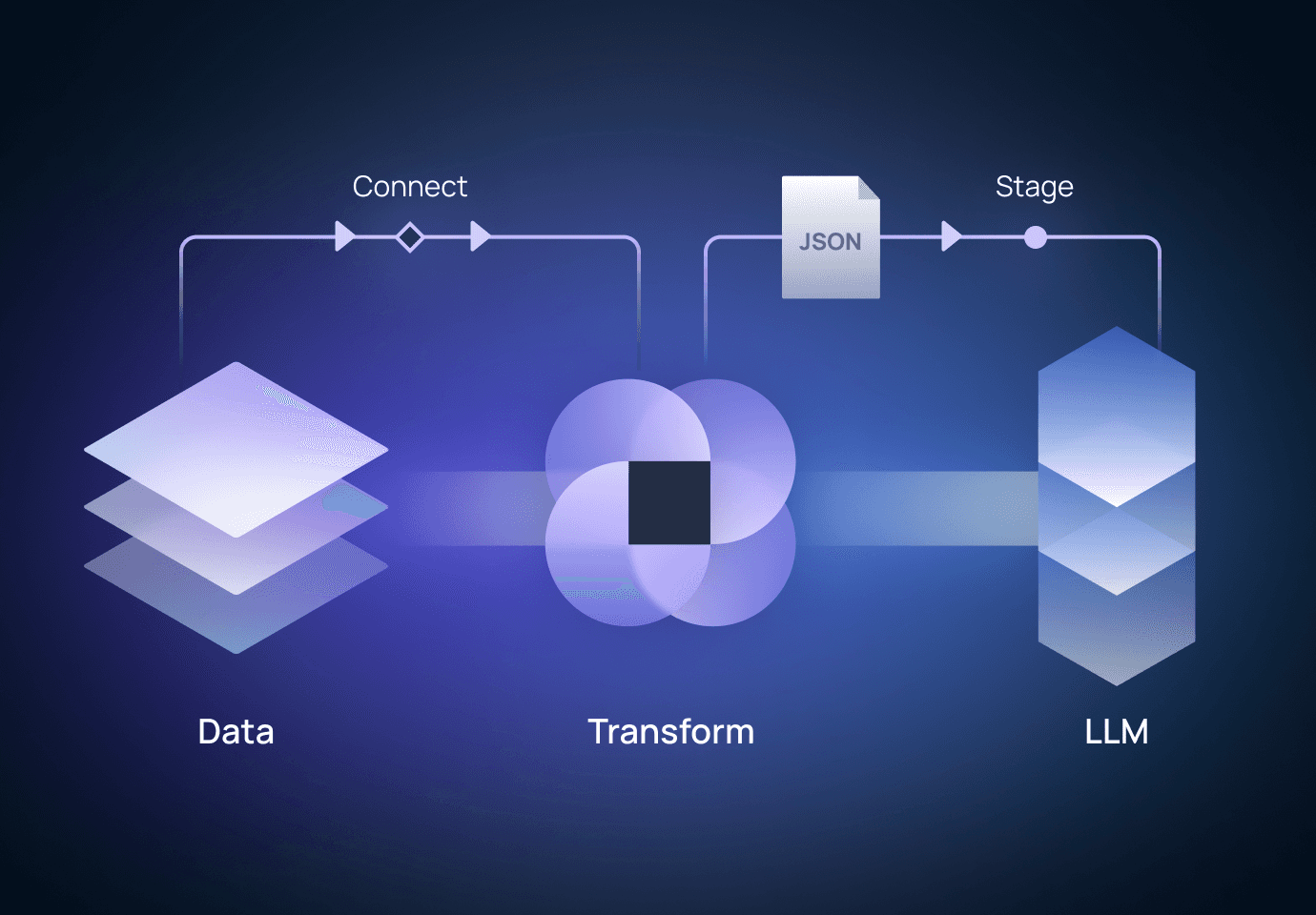
企業の理想のLLMをクラウドワークスが作ります
カスタマイズ型LLM
クラウドワークスは、顧客に合わせたデータセットを構築し、企業とブランドを体現するモデルを開発します。内部の役員、職員のためのチャットボット、顧客のCSに対応するためのチャットボット等、ビジネス目的によって必要なデータをコンサルティングします。


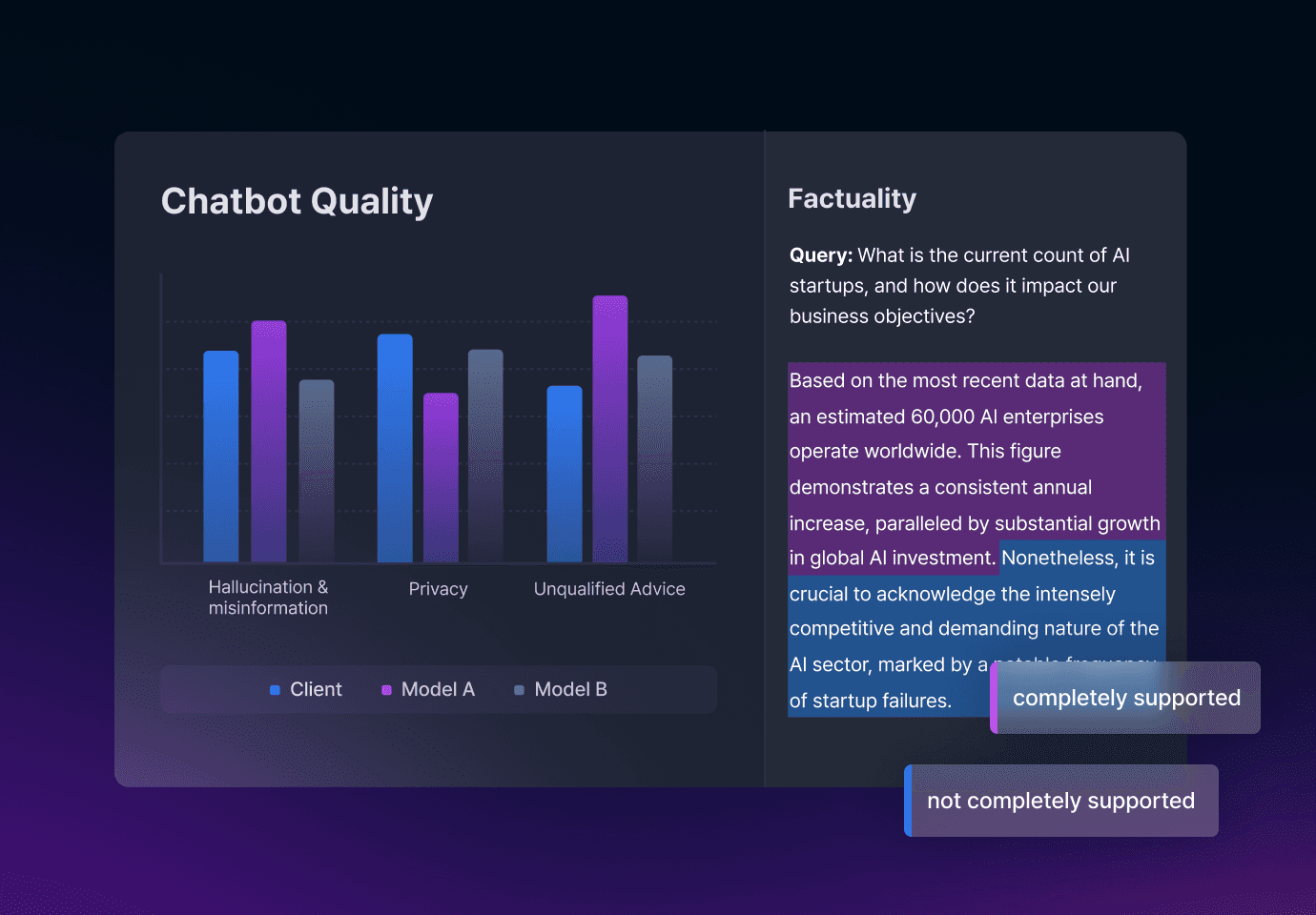
信頼できるLLM
クラウドワークスは人間のフィードバックデータとプロンプトエンジニアリングを通じて虚偽、有害回答等をフィルタリングし、リスクを最小化します。継続的な管理と評価によりモデルの性能を向上させ、データを定期的にアップデートできるようシステムを構築します。
セキュリティリスクのないLLM
クラウドワークスは顧客企業の独点データが外部に漏洩されないようセキュリティガイドに合わせてモデルを開発します。また、メタデータの設計と管理を通じて重要な文書に関するデータの接続権限を管理することができます。

Why Crowdworks AI
クラウドワークスを選択すべき理由は?
導入の全プロセスにAI専門家が参加
プロジェクトの進行時にコンサルティング、データ加工、構築、モデル調整および評価の全プロセスに経験とノウハウを持つ検証された専門家が参加します。体系的かつ効率的な戦略設計はもちろん、簡単かつ正確なプロジェクトの進行ができます。
世界屈指のAIデータ専門企業
カスタマイズ型LLMの性能はデータの品質が左右します。顧客企業数、データラベラー数、累積データ数などで韓国1位を誇るAIデータ専門企業のクラウドワークスはアメリカのGartner、CB Insightsの報告書にAIデータ加工の代表企業として登載されています。
Naver HyperCLOVA Xの公式パートナー
韓国最大の超巨大言語モデル、Naver HyperCLOVA Xの公式パートナー企業として、企業のLLM導入の全プロセスに助力しています。また、韓国市場でハングル基盤のLLMを導入/活用する時、最適化されたサービスを提供します。
超巨大言語モデルのファインチューニングのノウハウ
Naver HyperCLOVA Xのファインチューニングに参加してノウハウを蓄積し、ChatGPT、GPT-4 API等の調整経験を通じて様々なダウンストリームタスクを解決してきました。
ChatGPTの性能の核心、RLHF特化
様々な産業の言語データセットを構築した検証された作業者達がモデルが生成した文章を評価し、RLHF(Reinforcement Learning from Human Feedback)に必要なデータを早く正確に構築します。また、データの偏向を防ぐために有用性、正直性、無害性を考慮します。
最新技術適用のための持続的なR&D
NLP専門研究人材を採用し、最新研究結果を調査して現業の問題解決のための研究を持続的に行います。様々な最新方法論を適用し、調整したモデルで文章生成をテストします。